
Recognition of Images of Korean Characters Using Embedded
Networks
Sergey A. Ilyuhin
1,3
, Alexander V. Sheshkus
1,2
, Vladimir L. Arlazarov
2,3
1
Smart Engines Service LLC;
2
Federal Research Center “Computer Science and Control” of RAS, Moscow, Russia;
3
Moscow Institute of Physics and Technology, Moscow, Russia;
ABSTRACT
Despite the significant success in the field of text recognition, complex and unsolved problems still exist in this field.
In recent years, the recognition accuracy of the English language has greatly increased, while the problem of recognition
of hieroglyphs has received much less attention. Hieroglyph recognition or image recognition with Korean, Japanese or
Chinese characters have differences from the traditional text recognition task.
This article discusses the main differences between hieroglyph languages and the Latin alphabet in the context of
image recognition. A light-weight method for recognizing images of the hieroglyphs is proposed and tested on a public
dataset of Korean hieroglyph images. Despite the existing solutions, the proposed method is suitable for mobile devices.
Its recognition accuracy is better than the accuracy of the open-source OCR framework. The presented method of
training embedded net bases on the similarities in the recognition data.
Keywords: Hieroglyph recognition, embedded neural networks, character recognition, siamese neural network.
1. INTRODUCTION
Over the years, optical character recognition has been a popular research topic for computer vision specialists [1-6].
Convolutional neural networks have proven themselves as a good solution for such problems as object recognition. For
those networks, the number of outputs is equal to the number of characters of the recognizing alphabet. Such networks
are small and show high speed and recognition accuracy, for example, for the English language. However, this method
has difficulties in solving the same problem for the Korean language.
Hieroglyphs considerably differ from letters, for example, Korean hieroglyphs are always constructed from simpler
glyphs or keys. There are three groups of keys and a hieroglyph can be built from two or three keys from the different
groups. While keys from the first two groups are required in the hieroglyph, the key from the third group is optional.
There are , and keys in the first, second and third group respectively. Therefore, there can be
hieroglyphs constructed from three keys and constructed from two keys are possible. That yields to
different hieroglyphs in total.
The number of Korean hieroglyphs is times larger than the number of characters in the English alphabet (
against ). Therefore, classification neural network for hieroglyphs will have a huge amount of trainable
parameters and consequently will be hard in training and time-consuming in usage. Despite a big number of characters it
also exists an issue about the complexity of some hieroglyphs Fig. 1. Many hieroglyphs consist of small parts that could
be easily detected as a noise on the image or a part of the background. Such cases force developers and researchers to use
only high resolution and high scale images for recognition.
Figure 1. Example of complexity of hieroglyphs.
Another issue is the similarity of some hieroglyphs Fig 2. For these hieroglyphs, some minor changes could
transform one symbol to another one. This is why the background or some distortions that were made while taking the

picture of these symbols can confuse the classifier. In the context of training of classifier it problem put a limitation on
the augmentation of the training data.
Figure 2. Example of similarity of different hieroglyphs.
In omnifont hieroglyph recognition another problem arises. The appearance of a specific symbol can vary
considerably from font to font as shown in Fig. 3. One more problem for hieroglyphs is different in writing one symbol
through different fonts Fig 3. This problem is valid for all the languages but with hieroglyphs, the same symbol from
different fonts can vary more than different symbols from one font. For example, the first and the last symbols in Fig. 3
are less similar than the third and fourth symbols in Fig. 2. Therefore, we need to know a font or have additional
information to give a correct answer in some cases.
Figure 3. Example of one Korean symbol through different fonts.
Due to the large number of characters in the Korean language alphabet and their variability, it is necessary to enlarge
the size of the classification network by increasing the number of outputs in the last layer, which complicates its training
and increases the processing time for a one symbol image.
This article discusses the use of one of the alternative classification methods using the architecture of Siamese
networks [7] to train an embedded net, which is used in the face recognition problem [8].
2. RELATED WORK
2.1 Hieroglyphs Recognition
Image recognition solves the classification problem: it associates images with classes to which they belong. The
recognition quality of English text is at a very high-level [9]. Since the size of hieroglyphs alphabet exceeds
(while the alphabet for Latin-base languages is usually less than ) the recognition of hieroglyphs introduces new
challenges to both training and recognizing processes. One of the approaches to this task is to segment the characters into
keys, recognize them and then compose the final answer [10]. In this case, the neural network with thousands of outputs
is not required. Even though this method can solve the task it has drawbacks: non-robust to different image distortions
and the high dependence on the quality of the segmentation. Some authors use very large (more than
trainable
parameters) and deep neural networks which demonstrates outstanding quality but requires huge computational power
and cannot be used in mobile solutions [11, 12]. Another group of solutions deals only with the part of the alphabet [13].
In this case, some hieroglyph-specific problems fade and the recognition process can be build using classical approaches.
2.2 Embedded Nets
Embedded nets are commonly used instruments in the field of image recognition. The main idea of embedded nets is
to map input data to point in embedded space where points of similar data must be closer to each other than points of
different data; the more different the input data is, the greater the distance between their representations in embedded
space should be. For training, the embedded nets contrastive loss (Siamese architecture) [14] or the triplet loss (Triplet
architecture) [15] is used. Contrastive loss tries to maximize the distance between two samples from different classes and
minimize the distance between samples from the same class. Triplet loss is more complex, it is trying to maximize the
gap between distances for two samples of the same class and distance for samples from different classes, where one
sample is used in both cases. Embedded nets are being used for recognition [16, 17], verification [18], object tracking
[19]. The main advantage of this approach is that the size of the resulting neural network does not directly depend on the
size of the alphabet. This makes them very perspective in tasks with a large number of classes, for instance, in
hieroglyph recognition.
3. DATASET AND EVALUATION
We evaluate our method on the PHD08 dataset [20]. Which has images of Korean hieroglyphs of classes
( per class, nine different fonts). A total of binary images of hieroglyphs, all samples having a different
size, rotation, and distortions. An example of the final grayscaled Korean character input data is shown in Fig. 4.
Figure 4. Example of images of Korean symbol U+AC00 from PHD08 dataset
The accuracy() for classification was defined as:
(1)
Where
is the output label from classifier for image ,
is the ground truth output label for image , - total
number of images in the dataset.
is the indicator function which returns 1 if the statement is true and 0
otherwise.
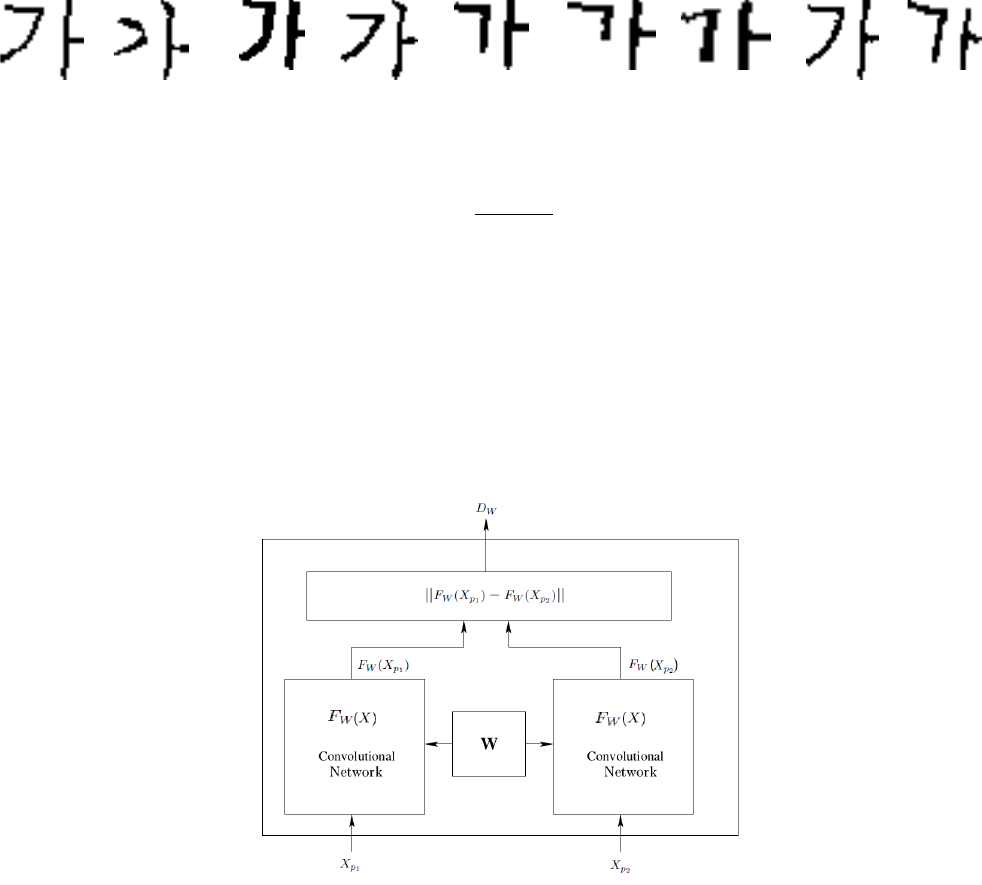
4. SIAMESE TRAINING METHOD
The Siamese training method was first introduced in 1990 to verify the signature in the context of the problem of
image matching [21]. For the training, process architecture consists of two twin networks, which receive different data at
the input, but whose outputs are connected by a layer of the distance function. This function finds the distance between
the representations of the last layers of networks. In this case, the configurable network parameters are the same for both
branches. This system has two key properties:
Figure 5. The training architecture.
• Consistency of representations: since the parameters of two neural networks are communicated, the representations
of a pair of very similar images cannot be very different.
• Symmetry: The answer that such a network will give to a pair of images will be the same regardless of which image
to which of the input layer is applied.
The training architecture shown In Fig 5.
5. USING EMBEDDED NET FOR CLASSIFICATION
After training embedded net we use training data to calculate representation of a reference sample of class for every
hieroglyph from the alphabet:

(2)
(3)
Where is a plurality of referent representation of symbols, is a plurality of symbols,
is - th image of
hieroglyph from training data which associates with
symbol, and is an operator of applying of embedded net.
The reference representation is obtained from the image of the character without any additions. Then using the method of
nearest neighbor we consider that the answer of the classifier is the symbol, whose reference representation will be closer
to the representation of the image received at the input:
(4)
Where is an answer of the classifier, is an input image of hieroglyph, is a metric in embedded space.
6. NET TRAINING
6.1 Train Data
Synthetically generated data was used to train the network [22]. For this, a background image was selected, on
which hieroglyphs were subsequently applied. For training, the entire alphabet of Korean hieroglyphs () was used
to make a correct comparison with other recognition systems. For testing, it was used as an open dataset that has only
characters from the Korean alphabet.
The next step is to cut out only the images of hieroglyphs from the images which were used, transform them to
grayscale, and sort by class. For better learning, the images of hieroglyphs are also augmented with projective
transformations and rotations [23]. In the end, there are pairs formed from the received images on which the net is being
trained.
6.2 Architecture of Embedded Convolution Neural Network
For the embedded net we have chosen architecture which is described in Table 1.
Table 1. Architecture of embedded net
Layers
#
Type
Parameters
Activation function
1
conv
filters , stride , no padding
softsign
2
conv
filters , stride , padding
softsign
3
conv
filters , stride , padding
softsign
4
conv
filters , stride , padding
softsign
5
conv
filters , stride , padding
softsign
6
conv
filters , stride , padding
softsign
7
fc
outputs
(5)
The contrastive loss function[24].
norm was used for training as the distance in the embedded space. The input
image size was , grayscale. The proposed architecture has only
weights. For comparison, the
classification net of the same architecture for the full alphabet will have
weights.
6.3 Pairs matching
In the initial experiment, we have generated all pairs randomly regardless of the presented symbol. The only
restriction is that we did not allow the reduplication of the pairs. We have also used image augmentation only for the first
image in the pair in the training process. Pair samples for the training are presented in Fig 6.

Genuine pairs
Imposters pairs
Figure 6. Examples of net training images.
6.4 Training
The network was trained on pairs of images of hieroglyphs. There was a total of pairs (for every class of
hieroglyph was chosen pairs of imposters and pairs of genuine), while the number of image pairs belonging to
one class was equal to the number of image pairs belonging to different classes. The data were randomly divided into
training and validation samples in a ratio of . The network was trained for epochs. The stochastic gradient
descent method was used as an optimizer.
Trained embedded net shows of . To compare the results we use the recently released version of
Tesseract 4.0.0 [9, 25], which reaches of . Comparing to Tesseract 4.0.0 our performance is better but still
is not sufficiently good. Important to note that the classification neural network of such an architecture did not converge
with default parameters. We hypothesize that this is due to the enormously large size of the last fully connected layer but
this question needs further research which is not the subject of the current work.
6.5 Pairs Matching Using Key Symbols
While analyzing the errors, we have found out that a neural network typically cannot distinguish similar hieroglyphs.
To address this problem and improve the classification quality we suggest to change the pairs generation process. Since
Korean hieroglyphs are combined from specific keys we can generate imposters using similar hieroglyphs that share
some of their keys. To study the amount of the shared keys we conducted two additional experiments.
In the first experiment, all imposters were sharing two keys. In this case, the neural network tries to find differences
between similar hieroglyphs and the quality should be increased according to the result of the error analysis. Fig. 7
illustrates different hieroglyphs which are sharing two keys. On the contrary, in the second experiment, we have created
an imposter pair from the hieroglyphs with zero shared keys to study the dependency between similarity in the training
data and classification quality.
Figure 7. Example of variability of keys for korean hieroglyphs.
7. RESULTS
Results of the initial and two additional experiments are presented in Table 2. The best quality is which is
achieved using similar hieroglyphs in imposter pairs. From the result, we can see that introducing similar but different
data is crucial and affects quality very much. In its best form, our method generates more than times fewer errors
than an open OCR engine Tesseract. The important property of the suggested method is that it allows us to train
relatively small neural networks that are possible to use on mobile devices and in other situations where computational
power is limited.
Table 2. Results
Embedded net
Tesseract OCR 4.0.0
0 keys
2 keys
random
26.78 %
60.83 %
48.84 %
37.67 %
8. CONCLUSION
In this work, we have proposed a method for the embedded neural network training for Korean hieroglyphs
recognition. Our study shows that the quality highly depends not only on the presence of different symbols in the training
data, but also on the similarity of the imposter pairs. The neural network, trained with the suggested method, has a very
small number of weights in comparison to the heavy state-of-the-art methods that require huge computational power. On
the contrary, the neural network trained with the suggested method can be used on mobile devices and in other special
cases with limited computational power. Still, in comparison with the Tesseract open-source OCR engine, our neural
network shows a very good quality.
In our future works, we plan to study this field further and generalize the pair generation method for different
languages and will try to rely not on the hieroglyph keys but the training process since in some tasks it is impossible to
obtain them. We will use the trained net answers instead of the information from the keys of hierogliphs, to extend and
improve our method for not systematic data. Along with that, we plan to improve the quality by using more complex
final space and loss function.
ACKNOWLEDGMENTS
This work is partially supported by the Russian Foundation for Basic Research (projects 17-29-03370, 17-29-07093).
REFERENCES
[1] K. Wang, B. Babenko, and S. Belongie, “End-to-end scene text recognition,” in 2011 International Conference on
Computer Vision, 1457–1464, IEEE (2011).
[2] M. Liao, J. Zhang, Z. Wan, F. Xie, J. Liang, P. Lyu, C. Yao, and X. Bai, “Scene text recognition from
two-dimensional perspective,” in Proceedings of the AAAI Conference on Artificial Intelligence, 33, 8714–8721
(2019).
[3] K. Bulatov, “A method to reduce errors of string recognition based on combination of several recognition results
with per-character alternatives,” Bulletin of the South Ural State University. Ser. Mathematical Modelling,
Programming & Computer Software 12(3), 74–88 (2019). 10.14529/mmp190307.
[4] X. Zhang, J. Zhao, and Y. LeCun, “Character-level convolutional networks for text classification,” in Advances in
neural information processing systems, 649–657 (2015)
[5] A. Noordeen, K. Kannan, H. Ravi, B. Venkatraman, and R. Milton, “Hierarchical ocr for printed tamil text,” in
Eleventh International Conference on Machine Vision (ICMV 2018), 11041, 110411G, International Society for
Optics and Photonics (2019).
[6] S. Gladilin, D. Nikolaev, D. Polevoi, and N. Sokolova, “Study of multilayer perceptron accuracy improvement
under fixed number of neuron,” Informatsionnye tekhnologii I ychislitelnye sistemy (1), 96–105 (2016).
[7] G. Koch, R. Zemel, and R. Salakhutdinov, “Siamese neural networks for one-shot image recognition,” in ICML
deep learning workshop, 2 (2015).
[8] Y. Taigman, M. Yang, M. Ranzato, and L. Wolf, “Deepface: Closing the gap to human-level performance in face
verification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 1701–1708 (2014).
[9] A. P. Tafti, A. Baghaie, M. Assefi, H. R. Arabnia, Z. Yu, and P. Peissig, “Ocr as a service: an experimental
evaluation of google docs ocr, tesseract, abbyy finereader, and transym,” in International Symposium on Visual
Computing, 735–746, Springer (2016).
[10] M. Franken and J. C. van Gemert, “Automatic egyptian hieroglyph recognition by retrieving images as texts,” in
Proceedings of the 21st ACM international conference on Multimedia, 765–768, ACM (2013).
[11] S.-G. Lee, Y. Sung, Y.-G. Kim, and E.-Y. Cha, “Variations of alexnet and googlenet to improve korean character
recognition performance.,” Journal of Information Processing Systems 14(1) (2018).
[12] Y.-g. Kim and E.-y. Cha, “Learning of large-scale korean character data through the convolutional neural network,”
in Proceedings of the Korean Institute of Information and Commucation Sciences Conference, 97–100, The Korea
Institute of Information and Commucation Engineering (2016).
[13] Y. Shima, Y. Omori, Y. Nakashima, and M. Yasuda, “Pattern augmentation for classifying handwritten japanese
hiragana characters of 46 classes by using cnn pre-trained with object images,” in Eleventh International Conference
on Machine Vision (ICMV 2018), 11041, 110412G, International Society for Optics and Photonics (2019).
[14] W. Zheng, Z. Chen, J. Lu, and J. Zhou, “Hardness-aware deep metric learning,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, 72–81 (2019).
[15] E. Hoffer and N. Ailon, “Deep metric learning using triplet network,” in International Workshop on
Similarity-Based Pattern Recognition, 84–92, Springer (2015).
[16] K. Sohn, “Improved deep metric learning with multi-class n-pair loss objective,” in Advances in Neural Information
Processing Systems, 1857–1865 (2016).
[17] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in
Proceedings of the IEEE conference on computer vision and pattern recognition, 815–823 (2015).
[18] K. Ahrabian and B. BabaAli, “Usage of autoencoders and siamese networks for online handwritten signature
verification,” Neural Computing and Applications (Nov 2018).
[19] B. Cuan, K. Idrissi, and C. Garcia, “Deep siamese network for multiple object tracking,” in 2018 IEEE 20th
International Workshop on Multimedia Signal Processing (MMSP), 1–6 (Aug 2018).
[20] D.-S. Ham, D.-R. Lee, I.-S. Jung, and I.-S. Oh, “Construction of printed hangul character database phd08,” The
Journal of the Korea Contents Association 8(11), 33–40 (2008).
[21] J. Bromley, I. Guyon, Y. Lecun, E. SГ¤ckinger, and R. Shah, “Signature verification using a siamese time delay
neural network.,” International Journal of Pattern Recognition and Artificial Intelligence - IJPRAI 7, 737–744 (01
1993).
[22] Y. S. Chernyshova, A. V. Gayer, and A. V. Sheshkus, “Generation method of synthetic training data for mobile ocr
system,” in Tenth International Conference on Machine Vision (ICMV 2017), 10696, 106962G, International
Society for Optics and Photonics (2018).
[23] A. V. Gayer, Y. S. Chernyshova, and A. V. Sheshkus, “Effective real-time augmentation of training dataset for the
neural networks learning,” in Eleventh International Conference on Machine Vision (ICMV 2018), 11041,
110411I, International Society for Optics and Photonics (2019).
[24] R. Hadsell, S. Chopra, and Y. LeCun, “Dimensionality reduction by learning an invariant mapping,” in 2006 IEEE
Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), 2, 1735–1742, IEEE
(2006).
[25] F. Asad, A. Ul-Hasan, F. Shafait, and A. Dengel, “High performance ocr for camera-captured blurred documents
with lstm networks,” in 2016 12th IAPR Workshop on Document Analysis Systems (DAS), 7–12, IEEE (2016).
